MetaMOOC (or, An Exploration into What Makes MOOCs Popular)
As some of you already know, I've decided to leave academia for industry. I'll be an Insight Data Science Fellow starting in June. I'm going to try to blog about my transition and public data projects I work on.
This time I'm writing about some exploratory analysis and prototyping I've been working on related to MOOCs. The online/hybrid learning space in general and MOOCs in particular are something I've been interested in. I wanted to see what I could learn from publicly available data. I quickly found that Coursera has a public API, which I used to download their course catalog. I wanted to understand what makes a course good or bad (or more used, watched, etc.) so I looked for publicly available course ratings/feedback. I found CourseTalk, which allows users to rate and review courses from many of the big MOOC providers. Some of the MOOC platforms (e.g. Udemy) allow ratings within the platform, but I couldn't find these within Coursera. Note that I picked these particular data sets to use somewhat arbitrarily. A future extension of this project would be to include all the major platforms and rating sites.
From CourseTalk I downloaded the average user rating of each course on Coursera. There was no API to do this, but the website was fairly easy to parse and extract the course ratings. I put both the course catalog and ratings into a MySQL database. I think that was overkill for this project, but I wanted to practice my database skils. Then I merged the data sets using the course title. This mostly worked, but I discovered that course titles are not unique. For example, there are two Coursera courses with the title "Machine Learning" (one by Andrew Ng and another by Pedro Domingos). Fortunately, this problem only affected 2% of courses, so I ignored it and moved on.
The first thing I looked at was the distribution of course ratings:
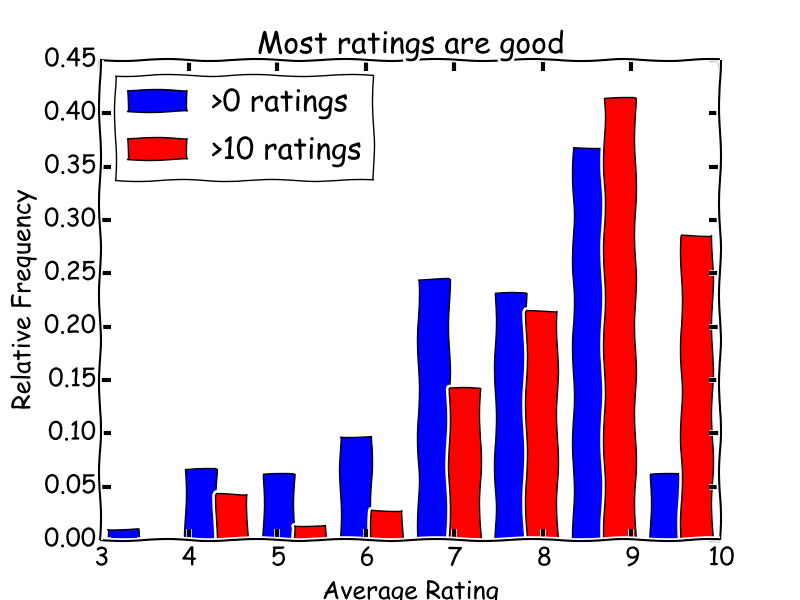
Most courses have good ratings. Initially this surprised me. CourseTalk uses a 5-star rating system with half stars allowed; I converted these ratings to a 0--10 scale. Most courses got 7/10 or higher, with 9/10 (i.e. 4.5 stars) being the most common rating. I don't think this just reflects the actual distribution of course quality. First, only about half of the courses had any ratings at all. Looking at only the courses with more than 10 user ratings (red bars), the distribution of courses that get a lot of ratings seems shifted to higher ratings. When I break up the ratings by popularity (as defined by the number of ratings), I find that more popular courses get higher ratings:
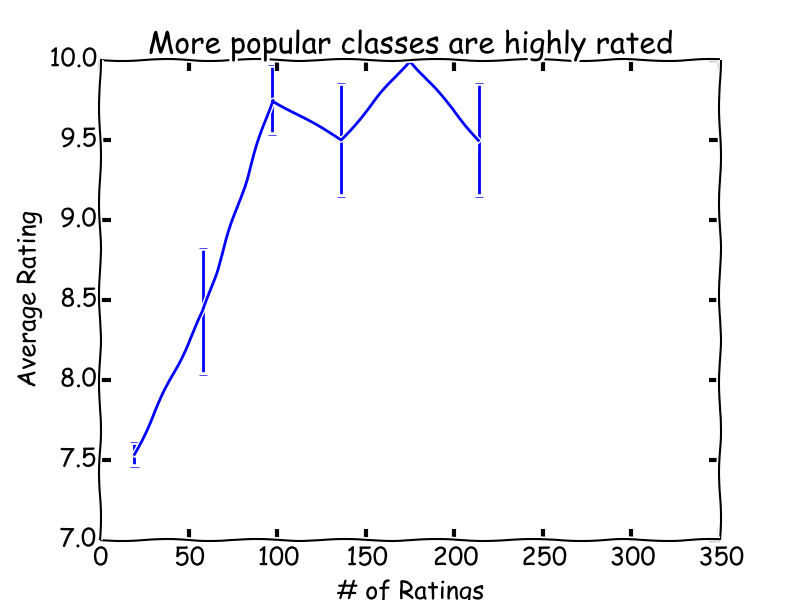
The average rating of a course improves as the number of users rating it grows to 100. Above 100 ratings, the rating saturates because 10 is the maximum rating possible. This effect isn't very surprising: it would be bizzare if the popular courses were worse on average. However, I think it helps explain the skewed distribution of ratings overall. My hypothesis is that courses that aren't very good tend not to get rated at all.
Next I looked at what features predict whether a given course is highly rated:
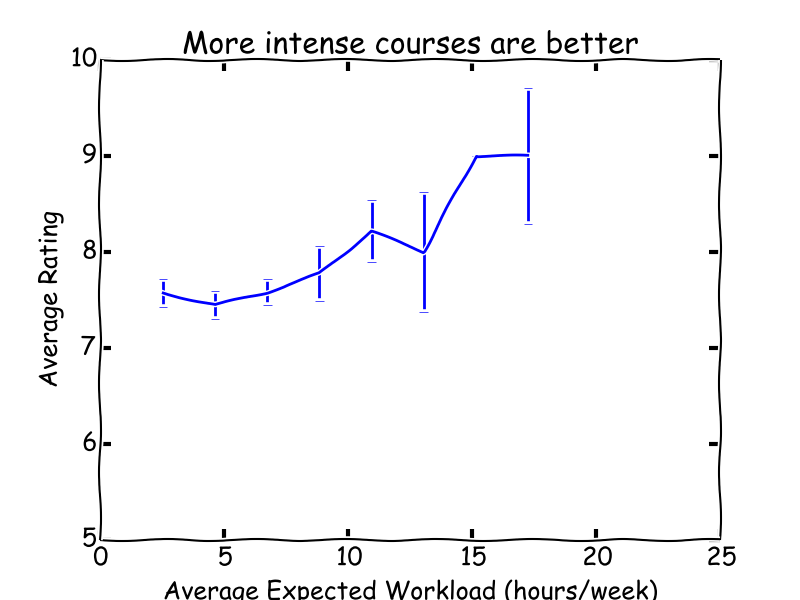
The Coursera catalog gives an expected workload in hours per week for each course. I found that courses that required more time got higher ratings. This surprised me too at first. What might be going on is that the low-workload courses are highly introductory/perfunctory, and that users think they get better return on investment in the courses that require more time commitment. However, I know that users actually prefer courses aimed at a lower background level:
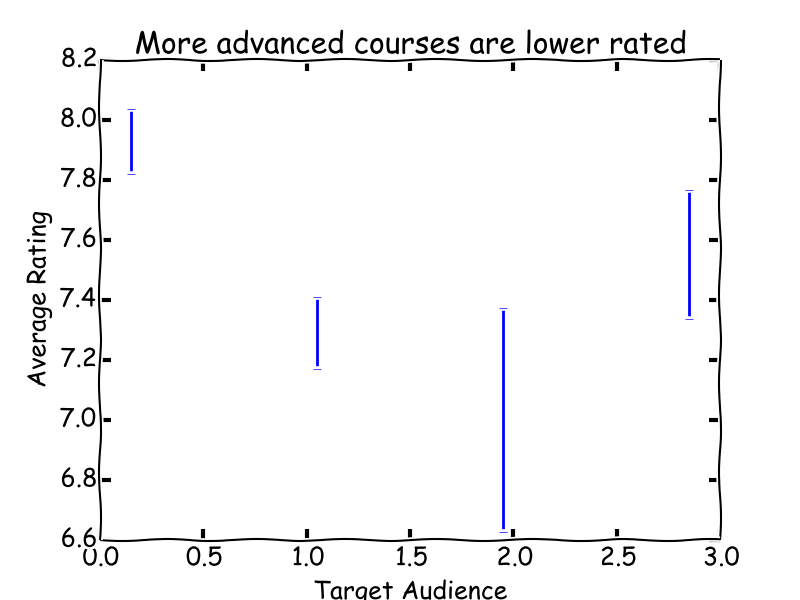
The catalog includes a target audience feature, where 0 means "basic undergraduates", 1 means "advanced undergraduates or beginning graduates", 2 means "advanced graduates", and 3 means "other." Courses aimed at basic undergraduates get the highest ratings. From the data, it looks like category 3 is not actually more advanced than category 2, but probably belongs near category 1 in terms of average audience. So my summary is that what users want most is a course at a basic undergraduate level, but that has a lot of content/opportunity to engage with the course.
There are more things to investigate in these data, but I also wanted to make some kind of data product with them. I decided to target casual users who haven't taken or rated many courses (this rules out typical collaborative filtering approaches). My protoypical user would be a first-time MOOC student who has a few ideas of what he wants but doesn't have a course in mind yet. I set out to create a product that would recommend a course based on the user's entered preferences.
The result so far is a page that lets users enter numerical preferences for course workload, difficulty, and popularity. Workload and difficulty are the features from the Coursera catalog I analyzed above. For popularity I used the number of ratings each course got on CourseTalk. I normalized these features to be on similar scales. The total score is the sum of these features, weighted by the user preferences. Essentially, this is using linear regression to predict which course a user would rate most highly. For a limited time, the recommender is available here (this server will not support high volume). One problem that is quickly apparent is that the scores are badly affected by outliers. For example, "An Introduction to Interactive Programming in Python" has an order of magnitude more ratings than any other course and almost automatically becomes the top suggestion if a user includes popularity. I've thought about applying some non-linear transformation to reduce this kind of outlier effect, but I haven't implemented anything yet.
Source code for this project, which I call "MetaMOOC," is available on github. The web app uses the Flask framework.
- Log in to post comments