Insight Weeks 1 and 2
Note: This is the first in a series of posts about my time at Insight Data Science.
I've been a Fellow at Insight Data Science for two weeks now. For such a short time, it's hard to believe how much has happened and how much I've learned. Although there are no formal classes, the program is very intense. Scheduled activities include a mix of technical workshops, presentations by data scientists working in industry, and mentoring sessions. But Insight is much more than just these scheduled activities. Most of the learning happens collaboratively and informally. Each Fellow is working on his or her own data project e.g. a predictive model, recommender system, or data visualization that leads to actionable insights. We're working on these projects just about every waking minute. The projects have to be done by the end of week 4. With so little time, it's imperative not to get stuck trying to learn something new that you don't understand. Fortunately with 30+ Fellows from different backgrounds, there's an expert in almost everything immediately available. For example, I used SQL a lot in academia so I've been answering questions about that. However, I had almost no prior experience with natural language processing, so I've been pestering the experts in that area.
A lot of what I worked on in week 1 was generating and developing project ideas. This is harder than I initially thought, and many Fellows (including myself) had to totally change projects during this time. For most of week 1, I was trying to do something based on the public Medicare data. A big part of Insight is showing project ideas to each other and getting feedback. The projects become part of our application portfolio so it’s important to learn whether others think they look impressive. The most important feedback I got about the Medicare idea was that for my insights to be convincing, I would need data from multiple time periods. Unfortunately, I was unable to find such data. As a result, that project is on hold for now.
Over the weekend, I worked on a new and completely different project (codename: reputon). My initial inspiration was the decision problem of whether to buy indie art (video games, music, etc.) that doesn't have informative reviews yet. I then decided that situation was unlikely to occur very often, but a similar problem can happen in online marketplaces: there's a product you want to buy that no one has bought yet. Should you take the risk? Based my own experiences, this situation doesn't happen too often either except for fairly unusual products with low volume. Usually, I can find another seller with a similar product that has a review. But, online marketplaces got me thinking about markets where the products are less perfect substitutes, in particular the housing market. I initially thought about Craigslist, but for now, I am working on Airbnb data.
The use case I am thinking of is: you are going on vacation and want an Airbnb, but you're booking late so availability is limited. You find a place that looks good online, but there are no reviews. I've been in that situation a few times before. What my product will do (I hope!) is predict how good that unreviewed room is going to be.
During week 2 I've been analyzing data and building predictive models. One of the first things I found is that the Airbnb rating distribution is very skewed:
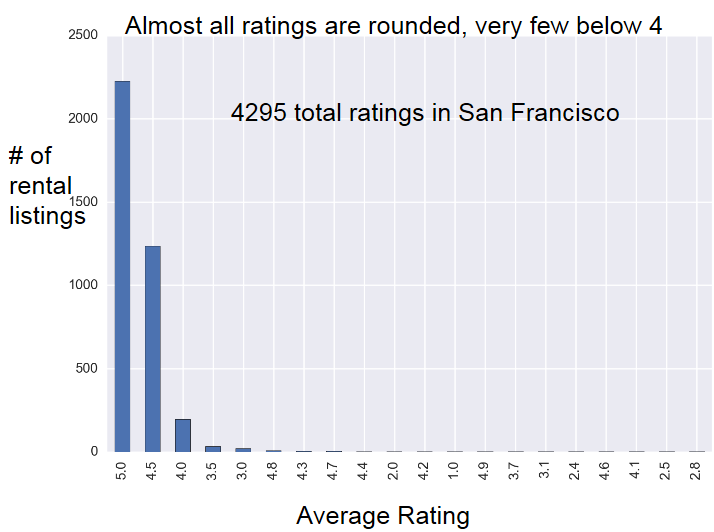
By far the most common ratings are 5 and 4.5. I expect that part of the skewness is due to Airbnb removing listings that consistently get bad reviews. (One of the other Fellows pointed out that owners might remove these listings too.) Remembering this skewness becomes critical in model evaluation. If one rating is much more common, a simple model can achieve very high accuracy by always predicting the most common rating. So the unmodified accuracy score is not a very good metric for model selection. Possible modifications include weighting or re-sampling based on the frequencies of different ratings. Note that these are overall ratings for each listing, not individual user ratings (which I don't have).
Now I'm working on predicting these ratings from information in the Airbnb listings. Possible features include the price, amenities (e.g. is there laundry), location, and the descriptions the owners write. Because almost all the data so far came in three discrete categories, I've been treating the problem as classification rather than regression. So far I've tried models based on logistic regression, support vector machines, and random forests. Random forests have had the best results, which are none too good:
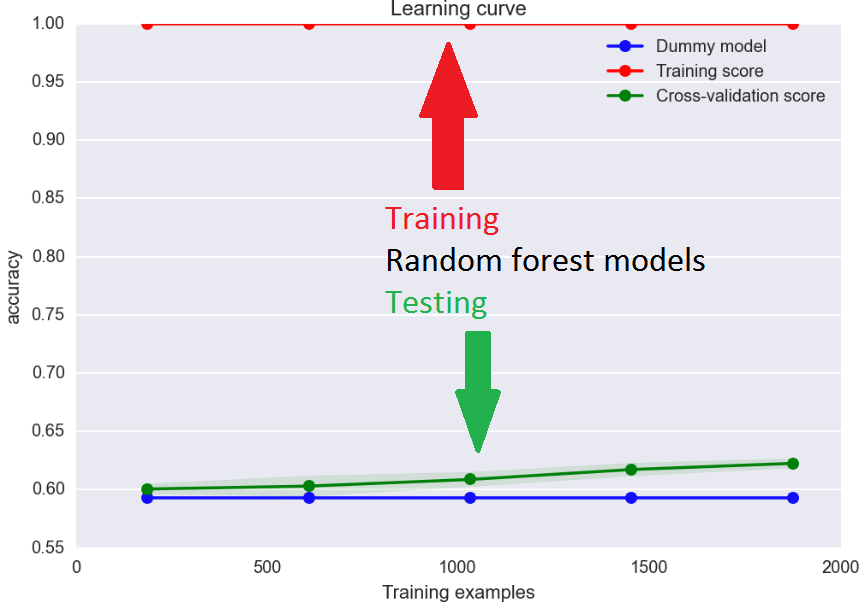
I haven't re-sampled the classes here, so I included a dummy model (blue) that always predicts a rating of 5. Thus, improvement above the blue line indicates use of the features to give results better than just guessing. The accuracy on new examples (green) is slowly increasing with more training data. I need either a lot more data (I've already collected 8x more) or significant optimization from the model hyperparameters. Note that the training score (red) is not particularly useful for random forests because by construction they almost always give the right answer for examples they've been trained on.
During week 2, I showed these results along with a skeleton version of my web app to some of the other Fellows. Not surprisingly, the main comments were that I needed to get the accuracy way up. This will be my main task in week 3. I got several suggestions for additional features to include. For example, one Fellow suggested a feature based on whether words were misspelled in the listing description.
In just these two weeks I’ve learned about topics ranging from what makes a good data project to natural language processing and how different companies are using data science. Beyond the knowledge, what has been really great about the program is the level of energy the staff, industry mentors, and other Fellows all bring to it. It makes me excited for what’s coming in week 3 and beyond.
- Log in to post comments